News
Guangdong BAIDU Special Cement Building Materials Co.,Ltd— 新闻中心 —
在免费的午餐决赛时代,IA的巨人付了“通行费”
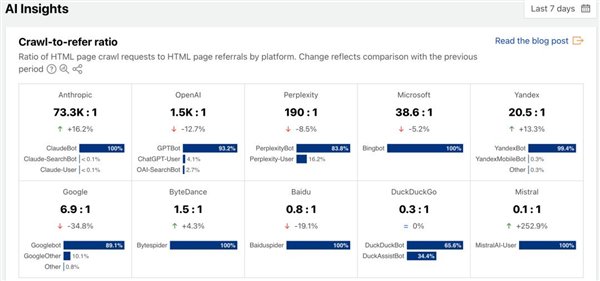 白宫二人组和特朗普最近进入了2.0时期。像这对幸福的敌人一样,外国社论团体与AI巨人之间也有爱与战斗。另一方面,有大型编辑想要与AI公司合作。数据表明,在搜索AI和Chatgpt出现后,全球网站的流量已减少。同时,“ IA巨人”通过数以万计的痕迹不断地忽略了跟踪器和侵蚀的协议。在这一点上,基础设施公司终于站起来,抓住了内容创建者的手,并说:“我们可以对AI巨人说不!” Cloudflare是控制世界网络流量约20%的互联网基础设施巨头,受到互联网用户为“ Cyberbodhisattva”的好评,并于2025年7月推出了一个实验市场和贸易市场。在一些shovelbraz中,此功能的本质将为网站的创建者提供“变化”。“”网络内容并培训模型,他们将无法像以前那样“吃免费的饭菜”。默认情况下,AI?网页已发布。搜索引擎(例如Google和Bing)将流量带到了他们的网站。借助流量,其网站通过广告或销售订阅获利。这是座右铭时代的看不见的合同。但是,在AI时代,传统搜索流量急剧下降,我计算得越多,它就会损失的越多。 IA公司将所有网络内容用作培训燃料,但很少需要奖励大多数创作者。当用户直接在AI聊天机器人中提出问题时,答案通常来自内容的摘要,而不是许多蓝色链接。甚至像Google这样的搜索巨头也在改变。他们过去曾提供网站链接的列表,但现在他们在搜索页面上启动了“人工智能的一般描述”。根据该报告,有75%的使用者在没有单击t的情况下会收到答案他链接。 2025年7月的最新CloudFlare数据表明,Google Trackers每6-7个痕迹单击一次返回,但OpenAI只需要1,500次。为了换取跳跃,人类的比例更加夸张,最多发生了73,300个变化。一家重要公司AI Crawlers带到其网站的点击百分比是图像来源:CloudFlare,这意味着传统的“内容交换贩运”模型失败了。与传统的搜索引擎相比,IA巨头已经吃了大量网站的内容,但这并不是“滴水”。这种不平衡使某些内容生产商变得更加困难。 “借助OpenAI,获得网站的流量比在Google时代要难的是750倍,而对于人类来说,它的困难是30,000倍。原因很简单:您正在消费原始内容的Lugar中。Cloudflare首席执行官Matthew Prince在博客中说:“这不是一个公平的待遇。公司并非没有攀登数据的价格。在过去的两年中,AI的巨人被指控“窃取内容”来训练大型模型,这导致全球对作者权利的需求浪潮,尤其是作者的权利,尤其是纽约时报等新闻机构,诸如纽约时报和开放诉讼诉讼诉讼的开放诉讼crawler de ia希望在网站上跟踪内容,您必须在网站上跟踪您的身份,并访问您的付款,并访问您的范围。开放的收入来源。DN,DDOS保护,DNS,零信托安全等。它在全球300多个城市中有节点,约有20%的网络流量,这提供了“中介”的便利性。 “ PAR PAR PAR CRAWL”建立在全球CDN网络的平均水平上。您可以在进入访问请求进入原始地点之前识别和处理AI爬行者。网站管理员可以为Cloudflare背景建立三种模式:允许,充电,块。网站管理员可以在后台建立许可证,计费或块|图像来源:CloudFlare所有Cloudflare网站最近默认地将IA跟踪器团结起来,除非网站管理员允许它们积极积极。仅在Cloudflar中建立合作的EAI公司可以参与付款机制。否则,您将被阻止。 AI爬行者URL Pagassi要求进行罢工,但尚未支付,CloudFlare将返回需要HTTP 402付款的状态代码。 AI爬行者可以向他们的申请表明他们接受支付既定价格。如果价格重合,它将推出,将返回200个OK,并将自动解决。 CloudFlare本身是该交易的“收银机”,负责添加发票和分发元素。 CloudFlare返回http 402付款申请的状态代码|图像来源:CloudFlare爬车手可以为应用程序提供付款信息|图像来源:Cloudflare HTTP 200 OK答案识别率|图像来源:CloudFlare是最重要的事情,用户代理的简单伪造就无法忽略这一点。 CloudFlare需要AI公司的注册密钥,以确保使用数字签名识别。这也是为了防止“错误的跟踪器”假装服从并避免付款。在过去耳胸引擎,但哪些页面不是RAW是对网站的“监视”,许多IA Traigators忽略了它。 CloudFlare解决方案改变了这一点,将现有的“限制”更改为基于robots.txt的“硬盖”。但是,根据Cloudflare的说法,目前只有10,000个主要域名中只有37%具有robots file.txt。 AI爬行者套件|图像来源:CloudFlare如果要打开一个Cloudflare帐户。阶段,该公司仍然对未来有很多想法。根据AI应用程序中的用户数量,并根据培训,推理,搜索等不同领域实施了更细微的价格策略。他们还认为,在智能代理商的世界中,每个愿景的付款跟踪器的真正潜力可能会产生。 “如果您的聪明的代理人以程序化的方式完美地工作会发生什么?想象一下您在深度研究助理中组织您的最新癌症研究,法律报告,Helping您是最适合自己的餐厅,并为这位智能代理提供最有用和最相关的内容的预算。不再是免费的。例如,可重复的内容当前占用大多数网页是m他认为,流量从未用精确度来衡量内容的价值。“如果您可以开始重视和重视内容,它不是基于它产生的流量,而是基于它所促进的知识数量(填充Motexististing人工智能中孔的孔数量的数量(Swiss Chisese或“ Swiss Cheese)或“瑞士奶酪”):无法帮助提高发动机以改善发动机以改善速度。实际上,广告收入正在增加,运输成本正在增加,有多少网站愿意向AI示踪剂开放以吸收血液,是否变得“关闭”了吗?同时,吸血含量的问题,但没有退出。 CloudFlare首席执行官,这一变化的新目标是“建立更好的互联网”。 “我们仍然不知道所有答案,但是我们正在与一些主要的经济学家和计算机科学家合作找到答案。”目前,其他CDN和安全供应商(例如Akamai)并未立即展示Amazon Cloudfront。将AI爬行者机器人远离DOOr |图像来源:Cloudflare Cloudflare的“抓取”似乎是CDN产品中的一项新功能。在搜索年龄,内容值通过访问用户召集了广告收入。但是,在AI时代,用户将永远不会停止点击网站。所有答案均由聊天机器人汇总和生成。您是否要免费为AI模型的在线内容建模或返回数据收集的“倒数”原则,以便创造者可以获得应有的薪酬?可以多少补偿?这项早期实验可以为新时代A的新时代经济铺平道路,无论成功或失败如何,其位置都清楚。人工智能无法以“开放性”的名义克服创作者的毅力,而是将人类的工作转变为自由燃料。 “该网络正在经历变化,其业务模式也将发生变化。在此过程中,将来有机会改善它,从最后一件事学习好东西30年。“正如Cloudflare Sehe认可自己,“这只是开始。” [本文的结尾]如果您需要重印,请务必向我们展示其来源:Kuai技术编辑:Ruofeng
白宫二人组和特朗普最近进入了2.0时期。像这对幸福的敌人一样,外国社论团体与AI巨人之间也有爱与战斗。另一方面,有大型编辑想要与AI公司合作。数据表明,在搜索AI和Chatgpt出现后,全球网站的流量已减少。同时,“ IA巨人”通过数以万计的痕迹不断地忽略了跟踪器和侵蚀的协议。在这一点上,基础设施公司终于站起来,抓住了内容创建者的手,并说:“我们可以对AI巨人说不!” Cloudflare是控制世界网络流量约20%的互联网基础设施巨头,受到互联网用户为“ Cyberbodhisattva”的好评,并于2025年7月推出了一个实验市场和贸易市场。在一些shovelbraz中,此功能的本质将为网站的创建者提供“变化”。“”网络内容并培训模型,他们将无法像以前那样“吃免费的饭菜”。默认情况下,AI?网页已发布。搜索引擎(例如Google和Bing)将流量带到了他们的网站。借助流量,其网站通过广告或销售订阅获利。这是座右铭时代的看不见的合同。但是,在AI时代,传统搜索流量急剧下降,我计算得越多,它就会损失的越多。 IA公司将所有网络内容用作培训燃料,但很少需要奖励大多数创作者。当用户直接在AI聊天机器人中提出问题时,答案通常来自内容的摘要,而不是许多蓝色链接。甚至像Google这样的搜索巨头也在改变。他们过去曾提供网站链接的列表,但现在他们在搜索页面上启动了“人工智能的一般描述”。根据该报告,有75%的使用者在没有单击t的情况下会收到答案他链接。 2025年7月的最新CloudFlare数据表明,Google Trackers每6-7个痕迹单击一次返回,但OpenAI只需要1,500次。为了换取跳跃,人类的比例更加夸张,最多发生了73,300个变化。一家重要公司AI Crawlers带到其网站的点击百分比是图像来源:CloudFlare,这意味着传统的“内容交换贩运”模型失败了。与传统的搜索引擎相比,IA巨头已经吃了大量网站的内容,但这并不是“滴水”。这种不平衡使某些内容生产商变得更加困难。 “借助OpenAI,获得网站的流量比在Google时代要难的是750倍,而对于人类来说,它的困难是30,000倍。原因很简单:您正在消费原始内容的Lugar中。Cloudflare首席执行官Matthew Prince在博客中说:“这不是一个公平的待遇。公司并非没有攀登数据的价格。在过去的两年中,AI的巨人被指控“窃取内容”来训练大型模型,这导致全球对作者权利的需求浪潮,尤其是作者的权利,尤其是纽约时报等新闻机构,诸如纽约时报和开放诉讼诉讼诉讼的开放诉讼crawler de ia希望在网站上跟踪内容,您必须在网站上跟踪您的身份,并访问您的付款,并访问您的范围。开放的收入来源。DN,DDOS保护,DNS,零信托安全等。它在全球300多个城市中有节点,约有20%的网络流量,这提供了“中介”的便利性。 “ PAR PAR PAR CRAWL”建立在全球CDN网络的平均水平上。您可以在进入访问请求进入原始地点之前识别和处理AI爬行者。网站管理员可以为Cloudflare背景建立三种模式:允许,充电,块。网站管理员可以在后台建立许可证,计费或块|图像来源:CloudFlare所有Cloudflare网站最近默认地将IA跟踪器团结起来,除非网站管理员允许它们积极积极。仅在Cloudflar中建立合作的EAI公司可以参与付款机制。否则,您将被阻止。 AI爬行者URL Pagassi要求进行罢工,但尚未支付,CloudFlare将返回需要HTTP 402付款的状态代码。 AI爬行者可以向他们的申请表明他们接受支付既定价格。如果价格重合,它将推出,将返回200个OK,并将自动解决。 CloudFlare本身是该交易的“收银机”,负责添加发票和分发元素。 CloudFlare返回http 402付款申请的状态代码|图像来源:CloudFlare爬车手可以为应用程序提供付款信息|图像来源:Cloudflare HTTP 200 OK答案识别率|图像来源:CloudFlare是最重要的事情,用户代理的简单伪造就无法忽略这一点。 CloudFlare需要AI公司的注册密钥,以确保使用数字签名识别。这也是为了防止“错误的跟踪器”假装服从并避免付款。在过去耳胸引擎,但哪些页面不是RAW是对网站的“监视”,许多IA Traigators忽略了它。 CloudFlare解决方案改变了这一点,将现有的“限制”更改为基于robots.txt的“硬盖”。但是,根据Cloudflare的说法,目前只有10,000个主要域名中只有37%具有robots file.txt。 AI爬行者套件|图像来源:CloudFlare如果要打开一个Cloudflare帐户。阶段,该公司仍然对未来有很多想法。根据AI应用程序中的用户数量,并根据培训,推理,搜索等不同领域实施了更细微的价格策略。他们还认为,在智能代理商的世界中,每个愿景的付款跟踪器的真正潜力可能会产生。 “如果您的聪明的代理人以程序化的方式完美地工作会发生什么?想象一下您在深度研究助理中组织您的最新癌症研究,法律报告,Helping您是最适合自己的餐厅,并为这位智能代理提供最有用和最相关的内容的预算。不再是免费的。例如,可重复的内容当前占用大多数网页是m他认为,流量从未用精确度来衡量内容的价值。“如果您可以开始重视和重视内容,它不是基于它产生的流量,而是基于它所促进的知识数量(填充Motexististing人工智能中孔的孔数量的数量(Swiss Chisese或“ Swiss Cheese)或“瑞士奶酪”):无法帮助提高发动机以改善发动机以改善速度。实际上,广告收入正在增加,运输成本正在增加,有多少网站愿意向AI示踪剂开放以吸收血液,是否变得“关闭”了吗?同时,吸血含量的问题,但没有退出。 CloudFlare首席执行官,这一变化的新目标是“建立更好的互联网”。 “我们仍然不知道所有答案,但是我们正在与一些主要的经济学家和计算机科学家合作找到答案。”目前,其他CDN和安全供应商(例如Akamai)并未立即展示Amazon Cloudfront。将AI爬行者机器人远离DOOr |图像来源:Cloudflare Cloudflare的“抓取”似乎是CDN产品中的一项新功能。在搜索年龄,内容值通过访问用户召集了广告收入。但是,在AI时代,用户将永远不会停止点击网站。所有答案均由聊天机器人汇总和生成。您是否要免费为AI模型的在线内容建模或返回数据收集的“倒数”原则,以便创造者可以获得应有的薪酬?可以多少补偿?这项早期实验可以为新时代A的新时代经济铺平道路,无论成功或失败如何,其位置都清楚。人工智能无法以“开放性”的名义克服创作者的毅力,而是将人类的工作转变为自由燃料。 “该网络正在经历变化,其业务模式也将发生变化。在此过程中,将来有机会改善它,从最后一件事学习好东西30年。“正如Cloudflare Sehe认可自己,“这只是开始。” [本文的结尾]如果您需要重印,请务必向我们展示其来源:Kuai技术编辑:Ruofeng